Logging to a database
Why log to a database?
Although logging events to files allows us to organise our logs and keep historic records for auditing purposes on a small number of hosts it rapidly becomes impractical as the number of hosts rises. We examined one potential solution, running a log server, in a previous chapter however even this solution soon reaches a scale where things begin to become unmanageable. Even in small networks there will be a large number of directories and an even larger number of log files to examine.
By storing all the log messages generated by all the computer systems, and other syslog capable devices, in our organisation in a central database we can solve these problems and, at the same, make automated analysis of these log messages even easier.
Creating the database
As this is a document describing the implementation of various system logging configurations, and not a guide on installing PostgreSQL, we shall assume that you have already installed and configured your database environment. If this is not the case then you may wish to refer to the guide.
Database users
Before we can create a database in which to store our log entries we first need to create some users. The first of these users will be used by the syslog-ng daemon to insert log entries into the database and will therefore not be assigned a password. The second of these users will be used when read access is required to the database and will be secured with a password.
Shall the new role be a superuser? (y/n) n
Shall the new user be allowed to create databases? (y/n) n
Shall the new user be allowed to create more new users? (y/n) npgadmin@lisa ~ $ createuser -P logviewer
Enter password for new user: ********
Enter it again: ********
Shall the new role be a superuser? (y/n) n
Shall the new user be allowed to create databases? (y/n) n
Shall the new user be allowed to create more new users? (y/n) npgadmin@lisa ~ $ createdb -O syslog syslog
pgadmin@lisa ~ $
Database structure
As with any database project there can be many schools of thought on exactly how the data should be organised. Some will wish to use a table for each host, others will prefer to use a table for each facility code. A similar discussion may occur when considering the area of data normalisation. Some will prefer the write efficiency which can be gained by storing data in a totally unnormalised form while others will prefer the index and storage space optimisations which can be achieved with highly normalised data.
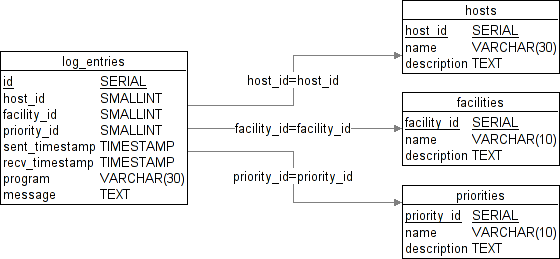
Because the decisions made with regard to data layout and normalisation will depend on many factors, including the number of hosts on your network and the number of messages which will be generated and recorded, we shall only discuss a single design in this section. It should be possible to easily modify the code presented here to use a different table structure or level of normalisation.
It can be seen from the diagram Figure 1 [Structure of the logging database] that we are using a single table to store all the log entries which we will receive and that we are normalising the data relating to host names, facility codes, priority levels and programs to reduce storage space, increase index efficiency and reduce the time taken to produce certain reports. We also include an additional field for each of these entries so that a meaningful description can be associated with them.
We can create this database structure using the following SQL commands.
CREATE TABLE hosts
(
host_id SERIAL NOT NULL,
name VARCHAR(30) NOT NULL CONSTRAINT UQ_host_name UNIQUE,
description TEXT,
PRIMARY KEY (host_id)
);
CREATE TABLE facilities
(
facility_id SERIAL NOT NULL,
name VARCHAR(10) NOT NULL CONSTRAINT UQ_facility_name UNIQUE,
description TEXT,
PRIMARY KEY (facility_id)
);
CREATE TABLE priorities
(
priority_id SERIAL NOT NULL,
name VARCHAR(10) NOT NULL CONSTRAINT UQ_priority_name UNIQUE,
description TEXT,
PRIMARY KEY (priority_id)
);
CREATE TABLE programs
(
program_id SERIAL NOT NULL,
name VARCHAR(50) NOT NULL CONSTRAINT UQ_program_name UNIQUE,
description TEXT,
PRIMARY KEY (program_id)
);
CREATE TABLE log_entries
(
id SERIAL NOT NULL,
host_id SMALLINT NOT NULL,
facility_id SMALLINT NOT NULL,
priority_id SMALLINT NOT NULL,
sent_timestamp TIMESTAMP WITH TIME ZONE NOT NULL,
recv_timestamp TIMESTAMP NOT NULL,
program_id SMALLINT NOT NULL,
message TEXT,
PRIMARY KEY (id),
CONSTRAINT FK_log_entries_to_host
FOREIGN KEY (host_id) REFERENCES hosts (host_id),
CONSTRAINT FK_log_entries_to_facility
FOREIGN KEY (facility_id) REFERENCES facilities (facility_id),
CONSTRAINT FK_log_entries_to_priority
FOREIGN KEY (priority_id) REFERENCES priorities (priority_id),
CONSTRAINT FK_log_entries_to_program
FOREIGN KEY (program_id) REFERENCES programs (program_id)
);
Creating database indexes
To improve the speed with which specific data can be retrieved from the database we can create indexes keyed on various fields. The code below will create indexes on the host field and the received timestamp field respectively. You will probably need to create additional indexes depending on your expected access patterns.
CREATE INDEX log_entries_by_host ON log_entries(host_id);
CREATE INDEX log_entries_by_date ON log_entries(recv_timestamp);
Indexes can also be created on multiple fields as shown below where we create an index on host, facility, priority level and program. Such indexes can be especially useful when running reports containing multiple GROUP BY and ORDER BY clauses.
CREATE INDEX log_entries_by_hflp ON log_entries(host_id, facility_id, priority_id, program_id);
You can even create an index on a part of a timestamp field as shown in the example below which creates an index based on the day of the week that the log message was sent. While such an index may be of little use in isolation a correctly designed index of this type can be used to greatly reduce the time required to process queries which use GROUP BY or ORDER BY clauses on timestamp parts.
CREATE INDEX log_entries_by_day_of_week ON log_entries(date_part('dow', sent_timestamp));
Creating a view
As we decided to store some of our data in normalised form we will need to create a view to allow this separated information to be accessed in a unified format. This can be easily accomplished using the SQL command below.
CREATE VIEW log_view AS
SELECT l.id, h.name AS host, l.recv_timestamp, l.sent_timestamp,
f.name AS facility, p.name AS priority, m.name AS program, l.message
FROM log_entries l, hosts h, facilities f, priorities p, programs m
WHERE l.host_id = h.host_id AND
l.facility_id = f.facility_id AND
l.priority_id = p.priority_id AND
l.program_id = m.program_id;
To allow data to be inserted into the view requires that a rule is composed which will describe to the storage engine how to normalise the data. An example of such a rule is given below.
CREATE RULE log_view_insert AS
ON INSERT TO log_view
DO INSTEAD
(
INSERT INTO hosts(name)
SELECT LOWER(NEW.host)
WHERE NOT EXISTS
(SELECT h.host_id FROM hosts h WHERE h.name = LOWER(NEW.host));
INSERT INTO facilities(name)
SELECT LOWER(NEW.facility)
WHERE NOT EXISTS
(SELECT f.facility_id FROM facilities f WHERE f.name = LOWER(NEW.facility));
INSERT INTO priorities(name)
SELECT LOWER(NEW.priority)
WHERE NOT EXISTS
(SELECT p.priority_id FROM priorities p WHERE p.name = LOWER(NEW.priority));
INSERT INTO programs(name)
SELECT NEW.program
WHERE NOT EXISTS
(SELECT m.program_id FROM programs m WHERE m.name = NEW.program);
INSERT INTO log_entries(host_id, facility_id, priority_id,
sent_timestamp, recv_timestamp, program_id, message)
(SELECT h.host_id, f.facility_id, p.priority_id, NEW.sent_timestamp,
NEW.recv_timestamp, m.program_id, NEW.message
FROM hosts h, facilities f, priorities p, programs m
WHERE h.name = LOWER(NEW.host) AND
f.name = NEW.facility AND
p.name = NEW.priority AND
m.name = NEW.program);
);
Whilst the above rule may look complex it is in fact fairly straight forward. Whenever the database server receives an INSERT command which would cause a row to be inserted into the log_view this rule is executed instead. As you can see there are four conditional INSERT commands which take care of inserting any records which do not already exist in the hosts, facilities, priorities and programs tables while the final INSERT command uses the values from these tables when storing the log entry.
Populating the tables
Now that we have created the tables which will hold our data we can populate them with the values which we know will be required on all configurations such as the names of the facility codes and the message priority levels. We can accomplish this using the SQL below.
INSERT INTO facilities(name, description) VALUES('auth', 'Authentication');
INSERT INTO facilities(name, description) VALUES('authpriv', 'Authentication');
INSERT INTO facilities(name, description) VALUES('cron', 'Scheduled tasks');
INSERT INTO facilities(name, description) VALUES('daemon', 'Daemon processes');
INSERT INTO facilities(name, description) VALUES('kern', 'Kernel messages');
INSERT INTO facilities(name, description) VALUES('local1', 'Local 1');
INSERT INTO facilities(name, description) VALUES('local2', 'Local 2');
INSERT INTO facilities(name, description) VALUES('local3', 'Local 3');
INSERT INTO facilities(name, description) VALUES('local4', 'Local 4');
INSERT INTO facilities(name, description) VALUES('local5', 'Local 5');
INSERT INTO facilities(name, description) VALUES('local6', 'Local 6');
INSERT INTO facilities(name, description) VALUES('local7', 'Local 7');
INSERT INTO facilities(name, description) VALUES('lpr', 'Printer');
INSERT INTO facilities(name, description) VALUES('mail', 'Mail');
INSERT INTO facilities(name, description) VALUES('news', 'News');
INSERT INTO facilities(name, description) VALUES('uucp', 'Unix to Unix Copy Protocol');
INSERT INTO facilities(name, description) VALUES('user', 'User processes');
INSERT INTO priorities(name, description) VALUES('emerg', 'Emergency');
INSERT INTO priorities(name, description) VALUES('alert', 'Alert');
INSERT INTO priorities(name, description) VALUES('crit', 'Critical');
INSERT INTO priorities(name, description) VALUES('err', 'Error');
INSERT INTO priorities(name, description) VALUES('warning', 'Warning');
INSERT INTO priorities(name, description) VALUES('notice', 'Notice');
INSERT INTO priorities(name, description) VALUES('info', 'Information');
INSERT INTO priorities(name, description) VALUES('debug', 'Debug');
Database permissions
REVOKE ALL ON hosts,facilities,priorities,programs,log_entries,log_view FROM public,syslog,logviewer;
REVOKE ALL ON facilities_facility_id_seq,hosts_host_id_seq,log_entries_id_seq,priorities_priority_id_seq,programs_program_id_seq FROM public,syslog,logviewer;
GRANT USAGE ON facilities_facility_id_seq,hosts_host_id_seq,log_entries_id_seq,priorities_priority_id_seq,programs_program_id_seq TO syslog;
GRANT SELECT ON hosts,facilities,priorities,programs,log_entries,log_view TO syslog,logviewer;
GRANT INSERT ON hosts,facilities,priorities,programs,log_entries,log_view TO syslog;
GRANT UPDATE ON hosts,facilities,priorities,programs TO syslog;
Testing the database
As our database, and especially the insert rule, is fairly complicated it is worth performing a quick test of the database to ensure that everything is working as desired before we attempt to configure syslog-ng to log to it. We can perform a simple test insert as shown below.
INSERT INTO log_view(host, facility, priority, sent_timestamp, recv_timestamp, program, message)
VALUES('test.internal.hacking.co.uk', 'kern', 'debug', '2007-02-27 11:45:00', '2007-02-27 11:45:01',
'N/A', 'A test kernel message');
Assuming that there were no error messages from the INSERT we can prove that the data has been stored by issuing the following SELECT command.
SELECT * FROM log_view;
If all goes well you should see the following output.
id | host | recv_timestamp | sent_timestamp | facility | priority | program | message
----+-----------------------------+---------------------+---------------------+----------+----------+---------+-----------------------
1 | test.internal.hacking.co.uk | 2007-02-27 11:45:00 | 2007-02-27 11:45:01 | kern | debug | N/A | A test kernel message
(1 row)
Database connection
Now that we have configured the database to be able to store our logs the only remaining task is to connect the syslog-ng daemon to the database. Assuming that we merged the app-admin/syslog-ng package with the sql use-flag set then the packages required for database access will have been installed and the syslog-ng daemon will recognise the sql destination type as shown in the example below.
destination d_pgsql {
sql(
type(pgsql)
host("localhost")
username("syslog")
database("syslog")
table("log_view")
columns("host", "recv_timestamp", "sent_timestamp", "facility", "priority", "program", "message")
values("$HOST", "$R_ISODATE", "$S_ISODATE", "$FACILITY", "$PRIORITY", "$PROGRAM", "$MSG")
indexes()
);
};
log { source(src); filter(f_not_debug); destination(d_pgsql); };
Unfortunately a great many messages generated by the kernel are not correctly prefixed with their subsystem name followed by a colon. The example destination and mapping above will therefore generate a large number of entries in the programs table which in fact represent kernel messages. A less than optimal solution to this problem, which logs kernel messages separately with a program name of N/A, is presented below however the correct solution would probably be to resolve the underlying issues in the kernel.
filter f_kernel { facility(kern); };
filter f_not_kernel { not facility(kern); };
destination d_pgsql_user
{
pipe("/var/log/database-pipe"
template("INSERT INTO log_view(host, recv_timestamp, sent_timestamp, facility, priority, program, message)
VALUES ('$HOST', '$R_ISODATE', '$S_ISODATE', '$FACILITY', '$PRIORITY', '$PROGRAM', '$MSG' );\n")
template-escape(yes));
};
destination d_pgsql_kernel
{
pipe("/var/log/database-pipe"
template("INSERT INTO log_view(host, recv_timestamp, sent_timestamp, facility, priority, program, message)
VALUES ('$HOST', '$R_ISODATE', '$S_ISODATE', '$FACILITY', '$PRIORITY', 'N/A', '$MSG' );\n")
template-escape(yes));
};
log { source(s_network);
source(s_user);
source(s_kernel);
source(s_internal); filter(f_not_debug);
filter(f_not_kernel); destination(d_pgsql_user); };
log { source(s_network);
source(s_user);
source(s_kernel);
source(s_internal); filter(f_not_debug);
filter(f_kernel); destination(d_pgsql_kernel); };